Cloud Materials Database (CMDB)
User ViewPoint
Usage Case Diagram Actors
General Description
The Cloud Materials Data Base (CMDB) offers homogeneous access to heterogenous data storage. Processes, linked to a CHADA and MODA definition, will be represented, and their different steps connected to material data. Upon uploading a certain file, the CMDB offers different data processing options to extract and generate semantic and relational data from the files. All data is then stored and interconnected for future retrieval.
Model
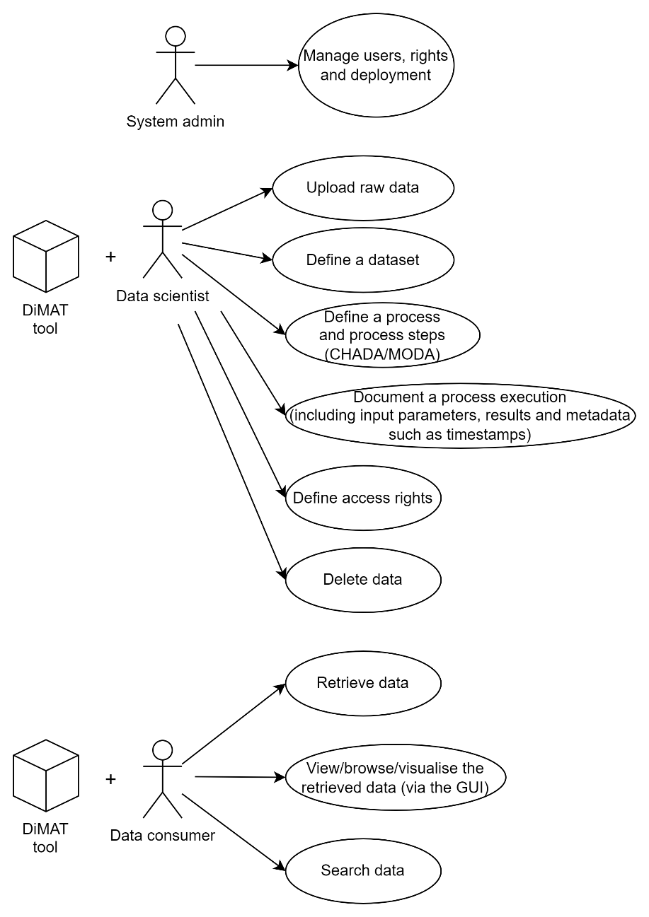
Roles
System admin: Has full control over the system and its management.
Data scientist: Generates data that will be stored in the CMDB.
Data consumer:: Browses the data stored in the CMDB.
Mockups
Activity 1
Create a new knowledge item
Add files to a knowledge item
Add metadata to a kItem
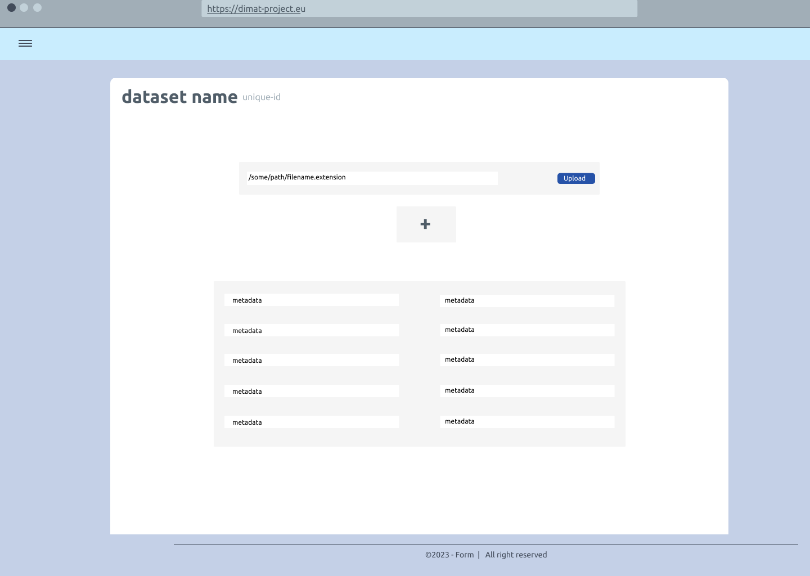
Activity 2
Browse all available knowledge items
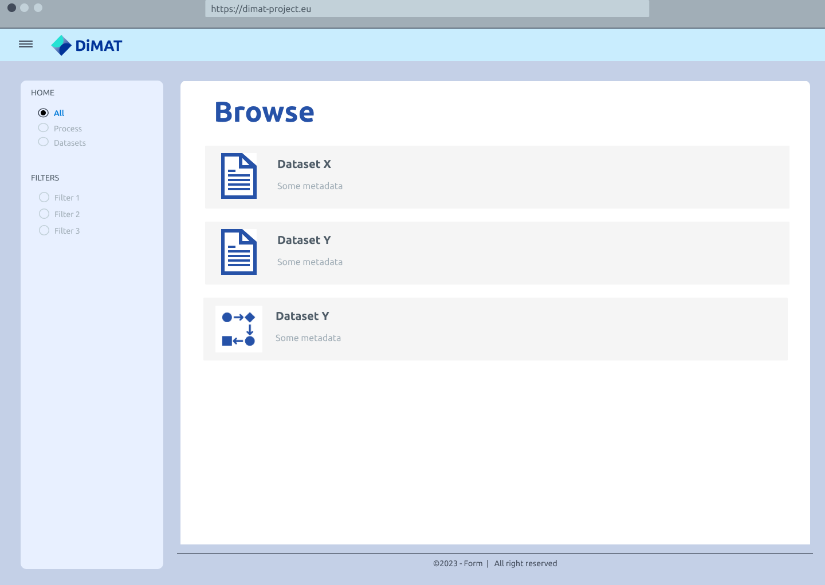
View a specific knowledge item
Functional ViewPoint
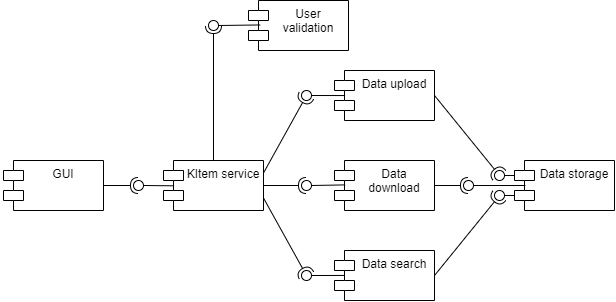
General architecture
Implementation ViewPoint
Architecture of Toolkits
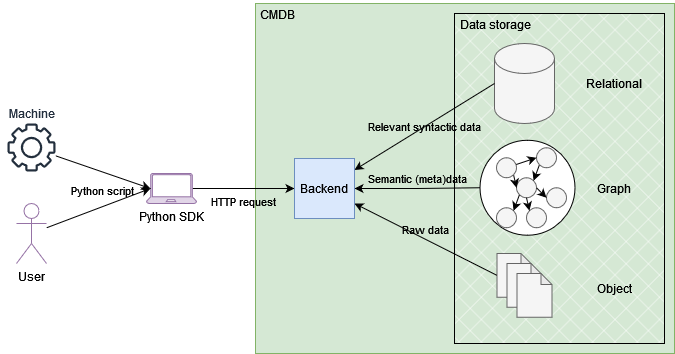
The CMDB offers a homogeneous storage solution for heterogeneous data. Relational, graph and object storage solutions are available and orchestrated via a central backend. Users (both human and machines) interact with the platform via the GUI or the Python SDK, with the user authentication component checking their identity. Internal data processing tools allow the pre-processing of the data to extract relevant knowledge prior to its storage.
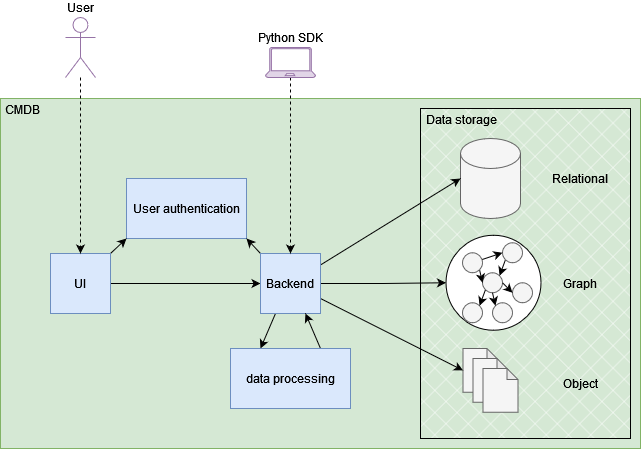
Required components
Hardware componentes
The only hardware requirement for deployment of the toolkit is an internet reachable server with enough available resources for handling the requests and sufficient storage for all the datasets that might be sent to the CMDB.
Data Storage
The core functionality of this toolkit is data storage. Three types of databases are required:
Relational: Tabular data extracted from the processed uploaded data.
Graph: Semantic data and metadata extracted from the raw file or defined by users.
Object storage: Storage of experimental raw files and other datasets.
Implementation Map
Data upload: The raw data coming for instance from a machine in a lab, is uploaded via the GUI, and additional metadata inputted in the upload form. This is sent to the backend, which may carry out additional data processing operations to extract relevant information from within the raw files. All data is then stored in the different databases, with unique identifiers to ensure consistency.
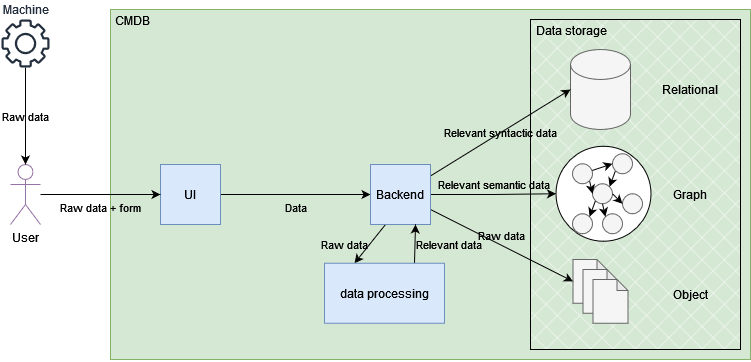
Data query via SDK: In this example, the GUI is circumvented, and the backend contacted directly. This allows people and machines (other DiMAT toolkits, for instance) to interact with toolkits via Python scripts. The method, in this case a query, is translated into the appropriate HTTP REST API request and sent to the backend, which gathers the relevant data from the different storages and provides a response.